



IT-Anleitung: Fernzugriff auf Linux-Maschinen (SSH, X2Go)
Einleitung
Um Linux-Maschinen aus der Ferne bedienen, können Sie entweder die Konsole (SSH) oder eine grafische Oberfläche (X2Go) nutzen. Damit können Sie persönliche oder eine der Poolmaschinen nutzen.
- Verbinden mit Secure-Shell (SSH)
- Fernzugriff von Windows (PuTTY)
- SSH-Authentifizierung mit Schlüsselpaar
- Verbindungen über mehrere Geräte (ProxyJump, Tunneln, sshuttle)
- Dateien kopieren und Verzeichnisse über SSH einbinden (scp, sshfs)
- Grafisches Arbeiten auf eigener oder Pool-Maschine (X11, X2Go)
- Verbindungen automatisch neustarten
- Sicherheit
- Unterstützung durch die IT-Abteilung bekommen
- Support
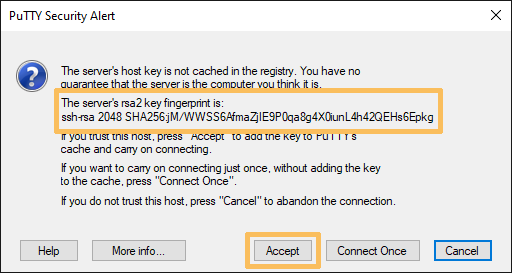
Mithilfe der Secure-Shell (SSH) kann eine gesicherte Fernverbindung auf der Kommandozeile aufgebaut werden. Verbinden Sie sich mit einem interaktiven Linux-Gerät, indem Sie desen Namen ansprechen, z.B. ssh konto@lx-pool.gsi.de. Ersetzen Sie konto dabei mit Ihrem Linux-Konto. Beim ersten Login fragt Sie das System, ob Sie die Zielmaschine zu Ihren bekannten Hosts (known hosts) hinzufügen möchten. Für Poolmaschinen sollten Sie vorher den angezeigten Fingerprint mit dem von der GSI veröffentlichten vergleichen (siehe Poolmaschinen). Bei einer Übereinstimmung können Sie mit yes gefolgt von Enter (representiert durch "↵") die Eintragung akzeptieren. Um sich von der SSH-Sitzung zu trennen nutzen Sie den Befehl exit.
» ssh konto@lx-pool.gsi.de↵ The authenticity of host 'lx-pool.gsi.de (140.181.70.153)' can't be established. RSA key fingerprint is b7:77:89:3d:96:d8:05:a3:6d:4b:17:5e:ed:81:1a:3e. Are you sure you want to continue connecting (yes/no)? yes↵ Warning: Permanently added 'lx-pool.gsi.de' (RSA) to the list of known hosts. konto@lx-pool.gsi.de's password:
In der Datei $HOME/.ssh/config können Sie Konfigurationen für SSH speichern. Die Datei besteht aus Blöcken. Die erste Zeile gibt an, worauf der Block zutreffen soll, z.B. mit Host, welches eine Liste von Hostnamen erwartet. Die Namen können mit Sternchen auch auf mehrere Hosts zutreffen. Darunter werden Optionen mit den zugehörigen Werten gelistet. Wenn Ihr Linux-Benutzername von dem auf Ihrem lokalen System abweicht, kann man sich bpsw. das konto@ in konto@lx-pool.gsi.de sparen, indem man die Option User setzt. Mit HostName kann sogar der Name des Ziels abgekürzt werden. Im folgenden Beispiel würde der Befehl ssh lxpool ausreichen, um sich am Pool anzumelden.
# Standardkonto für GSI/FAIR Host lxpool HostName lx-pool.gsi.de Host *.gsi.de User konto
Da die Verbindung zu einem Pool potentiell bei jedem Aufbau eine unterschiedliche Zielmaschine verwendet, ist CheckHostIP no eine weitere, gute Option. Ohne diese wird sich ssh jedes Mal beschweren, wenn es eine neue IP-Adresse sieht. Setzen Sie die Option daher am Besten für jeden Pool, den Sie nutzen.
Die Vorgehensweise für Windows ist grundsätzlich dieselbe, wie für Linux-Geräte. Der Hauptunterschied ist das eingesetzte Programm. Anstatt direkt ssh aufzurufen, wird ein Programm wie PuTTY genutzt. Im Bildschirmfoto können Sie sehen, wie damit eine Verbindung zu lx-pool.gsi.de eingerichtet wird.
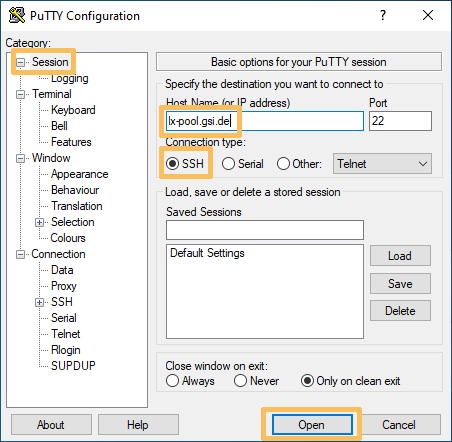
Wenn Sie sich zum ersten Mal an einem SSH-Server anmelden, müssen Sie dessen SSH-Schlüssel akzeptieren. Im vorhergehenden Teil wird erklärt, wie Sie diesen Schlüssel verifizieren können.
Das Arbeiten mit SSH kann durch SSH-Schlüssel in Verbindung mit ssh-agent (siehe unten) stark vereinfacht und gesichert werden. Für die Nutzung des GSI/FAIR Rechen-Clusters, ist die Nutzung von SSH-Schlüssel sogar eine Vorraussetzung.
Erstellen Sie ein SSH-öffentlich/privates-Schlüsselpaar mit dem Programm ssh-keygen auf Ihrer lokalen Maschine wie unten beschrieben. Der öffentliche Schlüssel ($HOME/.ssh/id_ed25519.pub) wird auf den Servern, zu denen Sie sich verbinden möchten, installiert, während der private Schlüssel ($HOME/.ssh/id_ed25519) auf Ihrer lokalen Maschine verbleiben muss. Es ist sehr wichtig, dass der private Schlüssel niemals einer anderen Person gegenüber offen gelegt wird. Denken Sie an automatische Backups, verlorene Laptos, alte Festplatten, usw. Der einzige Weg das Risiko unter Kontrolle zu halten, ist es ein starkes Passwort für den privaten Schlüssel zu nutzen.
Da die meisten Linux-Geräte an GSI/FAIR Ihr zentrales Heimatverzeichnis einbinden, müssen Sie Ihren öffentlichen Schlüssel nur auf ein Gerät hochladen. Nachdem Sie den Schlüssel installiert haben, wird ssh diesen automatisch nutzen und Sie nach dem Schlüssel-Passwort fragen, anstatt sich mit Ihrem Linux-Passwort anzumelden.
# Ein neues Schlüsselpaar erstellen » ssh-keygen -o -q -f ~/.ssh/id_ed25519 -t ed25519 # Das Passwort eines existierenden, privaten Schlüssels ändern » ssh-keygen -o -f ~/.ssh/id_ed25519 -p # Den öffentlichen Schlüssel auf dem Pool installieren » ssh-copy-id konto@lx-pool.gsi.de # Alternativ den Schlüssel händisch kopieren und Berechtigungen korregieren » cat ~/.ssh/id_ed25519.pub | ssh konto@lx-pool.gsi.de 'cat >>~/.ssh/authorized_keys' » ssh konto@lx-pool.gsi.de 'chmod 700 ~/.ssh; chmod 600 ~/.ssh/authorized_keys'
Um nicht bei jedem Aufruf von ssh das Schlüsselpasswort eingeben zu müssen, kann das Programm ssh-agent genutzt werden. Es handelt sich um einen kleinen Daemon (Hintergrundprozess), welcher Ihren unverschlüsselten, privaten Schlüssel sicher im Arbeitsspeicher zwischenspeichert. Normalerweise wird ssh-agent bei der Anmeldung gestartet (für GUI-Sitzungen bspw. beim KDE login). Sie können Ihren Agenten mit dem Kommando ssh-add verwalten.
# Prüfen, ob ein Agent verfügbar ist » ssh-add -l The agent has no identities. # ssh-agent läuft, aber es wurden noch keine Schlüssel hinzugefügt # Einen privaten Schlüssel zum Agenten hinzufügen » ssh-add ~/.ssh/id_ed25519 Enter passphrase for /home/konto/.ssh/id_ed25519: Identity added: /home/konto/.ssh/id_ed25519 (/home/konto/.ssh/id_ed25519) # Alle zwischengespeicherten Schlüssel auflisten » ssh-add -l 2048 2b:c5:77:23:c1:34:ab:23:79:e6:34:71:7a:65:70:ce .ssh/id_ed25519 (RSA)
Es ist oftmals notwendig sich auf einem Gerät anzumelden, nur um damit auf ein sonst unerreichbares Gerät zugreifen zu können. Bspw. braucht es beim Arbeiten über das Internet ein Gerät, welches Anfragen nach lustre.hpc.gsi.de weiterleiten kann. Da lx-pool.gsi.de aus dem Internet erreichbar ist, kann mithilfe der Pool-Knoten auf interne Ressourcen zugegriffen werden.
Die einfachste Lösung dafür ist die Option ProxyJump (-J, z.B. ssh -J konto@lx-pool.gsi.de konto@virgo-debian8.hpc.gsi.de). Diese ist relativ neu und wird daher unter Debian Jessie und CentOS 7 nicht unterstützt (weiter unten finden Sie Alternativen). Hier ist ein Beispiel, wie ProxyJump in einer Konfigurationsdatei genutzt werden kann. Damit kann die Anmeldung einfach mit ssh virgo-debian8 durchgeführt werden.
Host lxpool # Ein beliebiger Name, welchen Sie selbst setzen können HostName lx-pool.gsi.de # Der wirkliche Name von lxpool User $USER_AT_GSI # Ihr Linux-Konto an GSI/FAIR ForwardAgent no Host virgo-debian8 # Ein anderer, beliebiger Name Hostname virgo-debian8.hpc.gsi.de User $USER_AT_GSI ProxyJump lxpool # Der beliebig gewählte Name im vorherigen Block
Verbindungen zu mehreren Netzwerkports können durch einen SSH-Tunnel mit der Option -L geleitet werden: ssh -L lokaler-port:ziel-server:ziel-port ssh-server. Um bspw. Port 80 auf einem Webserver über den lokalen Port 8080 anzusprechen, würde man den Befehl ssh -N -L 8080:ein-webserver.gsi.de:80 lx-pool.gsi.de verwendent.
Dies kann verwendet werden, um Ihre SSH-Verbindung weiterleiten zu lassen. Dafür bauen Sie einen Tunnel auf (-L 22222:ziel-server:22) und nutzen diesen (ssh localhost:22222).
Eine andere Alternative ist sshuttle. Es implementiert eine transparente VPN-Verbindung über SSH. Damit können Sie bequem von extern auf GSI-Ressourcen zugreifen.
# Schicke alle Anfragen (selbst DNS-Anfragen) durch einen Tunnel zur GSI # Der Befehl wird zuerst nach Ihrem sudo- und danach nach Ihrem SSH-Loginpasswort fragen » sshuttle --dns --remote konto@lxpool.gsi.de --daemon --pidfile=/tmp/sshuttle.pid 0/0 # Nur Anfragen an einen bestimmten IP-Addressbereich (und keine DNS-Anfragen) weiterleiten » sshuttle --remote konto@lxpool.gsi.de --daemon --pidfile=/tmp/sshuttle.pid 140.181.64.0/18 # Verbindung trennen » kill $(cat /tmp/sshuttle.pid)
scp (secure copy) wird genutzt, um Dateien über SSH-Verbindungen zu kopieren. Um ein lokales Verzeichnis komplett (-r: rekursiv) in ein Verzeichnis in Ihrem Heimatverzeichnis zu kopieren, nutzen Sie den Befehl scp -r /lokaler/pfad konto@lx-pool.gsi.de:ziel/pfad/. Wenn Sie von dem entfernten Host auf Ihr lokales Gerät kopieren möchten, vertauschen Sie einfach die zwei Argumente (Quelle und Ziel). Falls Sie eine signifikante Menge an Daten kopieren möchten, können Sie eine alternative Verschlüsselungsmethode, wie Blowfish, mit -c blowfish wählen.
Mithilfe von sshfs können Sie entfernte Zielverzeichnisse auch als lokale einbinden. Damit können Sie Ihre lokalen Werzeuge, z.B. Ihren Text-Editor, nutzen, um entfernte Dateien zu bearbeiten.
# Das Verzeichnis path im Heimatverzeichnis unter dem lokalen Ordner /mnt/path einbinden » sshfs konto@lx-pool.gsi.de:path /mnt/path -C -o reconnect,auto_cache,follow_symlinks # Beenden der Einbindung » fusermount -u /mnt/path
Um auf interne Ressource, wie bspw. Lustre zuzugreifen, müssen Sie sshfs unter Umständen über andere Knoten, wie lx-pool.gsi.de tunneln. Dazu stehen Ihnen die weiter oben ausgeführten Möglichkeiten zur Verfügung:
- Mit
sshuttleein VPN zu lustre.hpc.gsi.de aufbauen und darübersshfsausführen. -
ProxyJumpin der Konfigurationsdatei setzen, oder als Option nutzen:sshfs -o ProxyJump=lx-pool.gsi.de lustre.hpc.gsi.de:/lustre /mnt/lustre. - Eine Portweiterleitung mit
ssh -f -N -L 22222:lustre.hpc.gsi.de:22 lx-pool.gsi.deeinrichten undsshfsden lokalen Port mit-p 22222übergeben.
Zum Aktivieren eines Tunnels für grafische Anwendungen (X11), nutzen Sie die SSH-Option -X. In einer Konfigurationsdatei kann diese Option mit ForwardX11 yes festgelegt werden. Allerdings ist X11-Forwarding langsam und unsicher. Darum werben wir für den Gebrauch von X2Go.
Mit X2Go können Sie aus der Ferne grafisch auf unserem Pool lx-pool.gsi.de und jede von der IT gemanagte Linux-Maschine arbeiten. Es ist vergleichbar mit dem Windows Terminal Server. Im Vergleich zu anderen Lösungen, wie VPN und X-Win32 hat X2Go die folgenden Vorteile:
- keine serverseitige Konfiguration oder Interaktion erforderlich
- bessere Leistung, vor allem über WAN-Verbindungen
- dynamisches Ändern der Größe des importierten Desktops
- keine Lizenzprobleme
- automatisches Tunneln via SSH (TCP Port 22)
Der Serverteil von X2Go ist auf jedem Linux system und der Client auf jedem Linux-Desktopsystem installiert. Unter Windows kann es mit dem Paket x2goclient aus dem Software-Center installiert werden.
Verbindung erstellen und starten
Um den Client unter Linux zu starten, können Sie das Kommando x2goclient oder den passenden Menüeintrag nutzen:
- KDE4: K → Applications → Internet → X2Go Client
- XFCE: x → Internet → X2Go Client
Bevor eine Verbindung gestartet werden kann, muss sie einmalig konfiguriert werden:
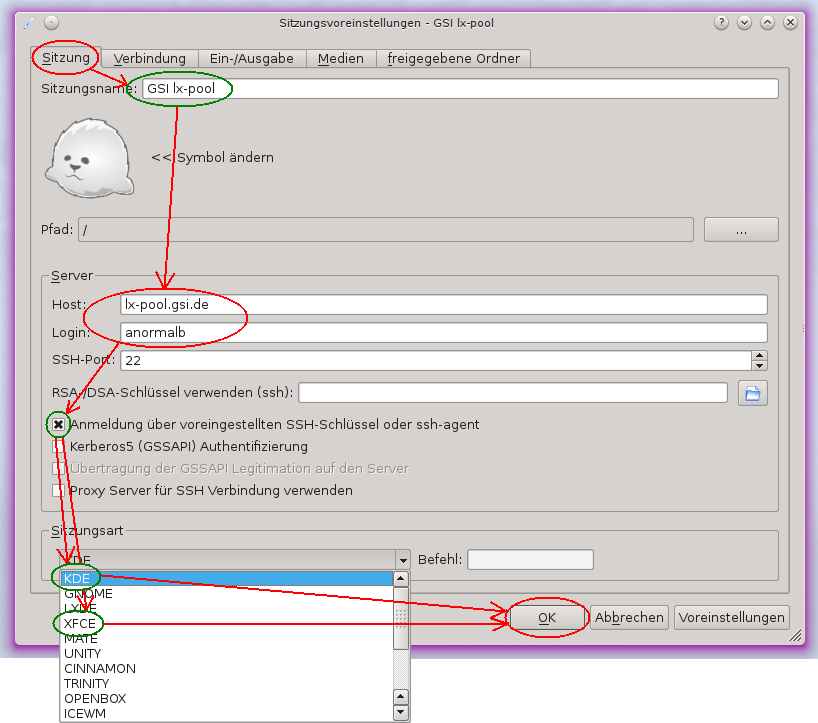
- Im Tab "Sitzung" unter "Sitzungsname" können Sie einen beliebigen Name für die Sitzung eingeben.
- Geben Sie den Hostnamen des Zielrechners und den Accountnamen für den Rechner in die Felder "Host" und "Login" und belassen Sie den "SSH-Port" auf 22.
- Falls Sie ein Schlüsselpaar für SSH verwenden, können sie die Box bei "Anmeldung …" auswähle. Wenn Sie Ihr Linux-Passwort verwenden möchten, wählen Sie die Box nicht aus.
- Als Letztes können Sie sich unter "Sitzungsart" für einen Desktop-Manager entscheiden. Die Standardeinstellung ist KDE. Wenn Sie XFCE nutzen möchten, wählen Sie es im Menü aus.
- Zum Abschluss speichern Sie die Verbindungseinstellung mit dem OK-Knopf.
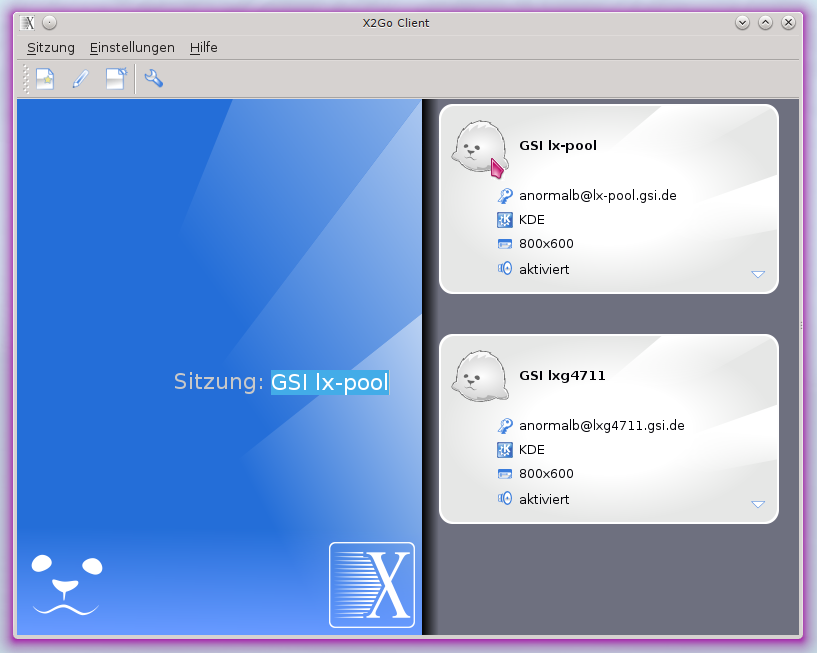
Klicken Sie auf eine verfügbare Verbindung. Wenn Sie sie zum ersten Mal nutzen, kann es sein, dass Sie den SSH-Schlüssel des Zielrechners akzeptieren müssen (siehe z.B. Poolmaschinen). Abhängig von Ihrer Authentifizierungsmethode, werden Sie vielleicht dazu aufgefordert Ihr Passwort oder Ihren geheimen SSH-Schlüssel anzugeben. Der Server startet daraufhin eine grafische Sitzung, auf welche Sie in einem neuen Fenster zugreifen können.
Verbindung beenden
Um eine ferngesteuerte Sitzung zu beenden, müssen Sie sich dort ausloggen:
- KDE4: K → Leave → Log out
- XFCE: x → Log Out
Wenn das X2Go-Fenster geschlossen wird, ohne sich abzumelden, führt dazu, dass die Sitzung offen bleibt. Sie können sich später dann einfach wieder verbinden. Dies ist aber nur bei dedizierten Maschinen nützlich. Wenn Sie einen Pool nutzen, werden Sie bei jeder Verbindung portentiell an eine andere Maschine weitergeleitet. Um eine einzelne Maschine aus einem Pool zu verwenden, nutzen Sie den Befehl host lx-pool.gsi.de und suchen sich dort eine aus.
Wenn der Host, mit dem Sie verbunden sind, Fehler haben sollte, z.B. wegen fehlerhafter Hardware, oder wenn er, wegen anderer Gründe, neu gestartet werden muss, verlieren Sie Ihre Verbindung. Es gibt Wege, wie die Verbindung automatisch aufgebaut werden kann.
Für SSH-Verbindungen kann das Programm autossh genutzt werden. Es verbindet sich automatisch neu, wenn es eine geschlossene Verbindung feststellt. Normalerweise nutzt es einen anderen Port als SSH (Port 22), um darüber einen Heartbeat zu senden. Diese Nachrichten können (und müssen) auch über die SSH-Verbindung gesendet werden, wenn der Port auf Null gesetzt wird (-M 0).
autossh -M 0 $USER@lxlogin.gsi.de # oder erst exportieren, für alle folgenden Befehle export AUTOSSH_PORT=0 autossh $USER@lxlogin.gsi.de # oder die Einstellung in der .bashrc persistent machen export AUTOSSH_PORT=0 >>~/.bashrc . ~/.bashrc autossh $USER@lxlogin.gsi.de
Wenn autossh sich wieder neu verbindet, erhalten Sie eine neue SSH-Verbindung. Befehle, die Sie in der alten ausgeführt haben, werden höchstwahrscheinlich beendet. Um dies zu verhindern, nutzen Sie bitte einen Terminal-Multiplexer, wie screen oder tmux auf der Zielmaschine.
autossh kann auch genutzt werden, um sshuttle zu automatisieren. Leider liefert sshuttle aber einen unpassenden Statuscode, wenn die Verbindung beendet wird. Das kann jedoch mit einem kleinen Skript behoben werden.
# das Skript anlegen (nur einmal) cat <<CODE >~/sshuttle-in-autossh #!/bin/sh sshuttle "$@" [ $? -eq 99 ] && kill -s USR1 $$ CODE # autossh mit dem Skript ausführen AUTOSSH_PATH=~/sshuttle-in-autossh autossh -M 0 -- -r $USER@lxlogin.gsi.de 140.181.0.0/32
Ein voll funktionierendes SSH-Konto ist eine sehr wertvolle Ressource für böswillige Aktivitäten. Es ist daher sehr wichtig auf die Sicherheit zu achten. Leider können die meisten Sicherheitseinstellungen nicht forciert werden, bzw. würde dies die Nutzbarkeit stark einschränken. Der generelle Rat ist:
- Nutzen Sie ein starkes Passwort für Ihr Konto.
- Nutzen Sie ein starkes Passwort für Ihre privaten Schlüssel.
- Nutzen Sie niemals unverschlüsselte, private Schlüssel.
- Nutzen Sie, wenn verfügbar, Schlüssel vom Typ
ed25519stattRSA. - Nutzen Sie
-obeissh-keygen, da dies in älteren Versionen einen viel besseren Schutz gegen Brute-Force-Attacken ermöglicht. - Nutzen sie kein Agent-Forwarding. Stattdessen können Sie auf der Kommandozeile
-Joder in der KonfigurationsdateiProxyJumpverwenden. - Nutzen Sie X11-Forwarding nur wenn notwendig.
Wenn etwas nicht funktionieren sollte, können Sie über die Support-Email-Adresse linux-service @ gsi.de ein Ticket erstellen. Für Probleme mit SSH hängen Sie dem Ticket bitte den Debug-Output Ihres SSH-Kommandos an, indem Sie SSH mit der Option -vvv ausführen.
Support
- Support-Email: linux-service @ gsi.de