The Active Buffer Board (ABB) as example of a PCI device in DABC
Description of the board
The ABB is developed by Institut f. Technische Informatik at Uni Mannheim.Plain tests of board and driver
Results of some previous tests of ABB and driver is described here (limited access).DABC class description and functionality
$ dabc::PCIBoardDevice : Subclass of dabc::Device. Adapter to the the mprace::Board functionality, i.e. the generic PCIe.-
- Keeps vector of mprace::DMABuffers (mapped user memory taken from regular dabc::MemoryPool). Method
GetDMABuffer(dabc::Buffer*)delivers the mapped DMA buffer which corresponds to a given memory pool buffer; these are associated by the dabc::Buffer id number used as index of the DMA buffer vector. The (re-)mapping is done on the fly if needed, callingMapDMABuffers(dabc::MemoryPool*). - Method
ReadPCI(dabc::Buffer*)implements reading one buffer from PCI, with regard to parameters fReadAddress, fReadBAR, fReadLength, resp. Performs DMA into a regular pool buffer (user memory) which is mapped usingGetDMABuffer(dabc::Buffer*). Currently DMA is still initiated by the host PC, i.e. ABB will start transfer by the call ofReadDMA()that blocks until DMA is complete. For asynchronous DMA (double buffering of dabc::DataTransport) following methodsReadPCIStart()andReadPCIComplete()are provided. Device subclass may re-implement this method, adding board specific stuff. - Method
ReadPCIStart(dabc::Buffer*)implements start reading one buffer from PCI, with regard to parameters fReadAddress, fReadBAR, fReadLength, resp. Performs DMA into a regular pool buffer (user memory) which is mapped usingGetDMABuffer(dabc::Buffer*). This call does not block until DMA is complete, but returns immediately! Device subclass may re-implement this method, adding board specific stuff. - Method
ReadPCIComplete(dabc::Buffer*)does a blocking wait until the current DMA buffer is finished with read from PCI. DMA has to be started usingReadPCIStart()before; method returns error if there was no DMA going on. Device subclass may re-implement this method, adding board specific stuff. - Implements
CreateTransport()as framework factory method to create a dabc::PCITransport and assign own working thread for each transport. - Implements several specific commands which are handled in
ExecuteCommand(Command*). Currently these commands define DMA address regions for reading and writing. - Implements
DoDeviceCleanup()for cleaning the mapped dma buffers. $ dabc::PCITransport : Subclass of dabc::DataTransport, providing the connection to a module's input port. - Transport queues and backpressure mechanism is provided by base class. The IO actions are executed in the thread assigned to the base class dabc::WorkingProcessor.
- Implements
ProcessPoolChanged(dabc::MemoryPool*). This method is called whenever the memory pool associated with the transport changes, e.g. by recreation, expansion, etc. UsesPCIBoardDevice::MapDMABuffers(dabc::MemoryPool*)to rebuild the indexed mprace::DMABuffers for each buffer of the pool. - Implements
ReadBegin(), returning the size of the next buffer that should be read from board. Uses current values as set in the dabc::PCIBoardDevice - Implements
ReadPrepare(dabc::Buffer*)which initiates the actual reading of the buffer passed as argument. CallsPCIBoardDevice::ReadPCIStart(dabc::Buffer*). Note that on return ofReadPrepare(), the previously filled DMA buffer is already forwarded to the connected port (which wakes up thread of the readout module), i.e. dabc::DataTransport implicitly provides a double-buffering mechanism here. - Implements
ReadComplete(dabc::Buffer*)which returns when the actual buffer has finished being filled from DMA read operation. CallsPCIBoardDevice::ReadPCIComplete(dabc::Buffer*). $ dabc::AbbDevice : Subclass of dabc::PCIBoardDevice. - Re-Implements
ReadPCI(): NOTE: To work with the bnet test example, this will copy an event header of the bnet format (i.e. incrementing event count and unique id) into each output Buffer afterdabc::PCIBoardDevice::ReadPCI()is complete. Later CBM event format must be written by ABB and implemented in bnet for ABB. - Implements
DoDeviceCleanup()to reset event counter for the bnet test example. $ dabc::AbbReadoutModule : subclass of dabc::ModuleAsync; generic implementation of a readout module to use the PCIBoardDevice. - Creates the memory pool which is used for DMA buffers in the PCIBoardDevice; this pool is propagated to the device via the PCITransport when module is connected, since device will use the pool associated with the connection port.
- Module runs either in standalone mode (one input port, no output) for testing; or in regular mode (one input port, one output port)
-
ProcessUserEvent()defines the module action for any dabc events, e.g. input port has new buffer. In standalone mode, received buffer is just released. In regular mode, buffer is send to the output port. $ dabc::AbbWriterModule : subclass of dabc::ModuleSync; generic implementation of a writer module to use the PCIBoardDevice. - Creates the memory pool which is used for DMA buffers in the PCIBoardDevice; this pool is propagated to the device via the PCITransport when module is connected, since device will use the pool associated with the connection port.
- Module runs either in standalone mode (one output port, no input) for testing; or in regular mode (one input port, one output port)
-
MainLoop()defines the module action. In standalone mode, a new buffer is taken from the memory pool and send to the output port. In regular mode, the send buffer is taken from the input port. $ dabc::AbbFactory : subclass of dabc::ApplicationFactory. Generic plugin to utilize ABB classes in a set up: - Implements
CreateDevice()for the AbbDevice. Third argument of this factory method is dabc::command, containing initial setup parameters of the device. - Implements
CreateModule()for the AbbReadoutModule and the AbbWriterModule. Third argument of this factory method is dabc::command, containing initial setup parameters of the module. - Factory is created automatically as static (singleton) instance on loading the
libDabcAbb.so.
- Keeps vector of mprace::DMABuffers (mapped user memory taken from regular dabc::MemoryPool). Method
ABB classes with bnet test example
The TestWorkerPlugin of the bnet/test example was modified to optionally integrate ABB. $ bnet::TestWorkerPlugin : subclass of bnet::WorkerPlugin. This example has possibililty to utilize ABB classes in a bnet-set up.-
- Registers parameters to configure the ABB. Note: The Parameter names are defined as string constants in
AbbFactory.h. These same names are used by AbbFactory methods to get the appropriate command parameters! - Implements
CreateReadout()with optional AbbDevice. May either use the AbbDevice, or still use the TestGeneratorModule of the example. This is switched by configuration parameter via theReadoutPar()value (either "ABB", or anything else).Connects AbbDevice directly with the input port of the combiner module; we do not use dabc::AbbReadoutModule here (this is applied for standalone exampleabb_testonly).
- Registers parameters to configure the ABB. Note: The Parameter names are defined as string constants in
DABC Performance measurements (new design and bitfile, May 2008)
Standalone mode with AbbReadoutModule
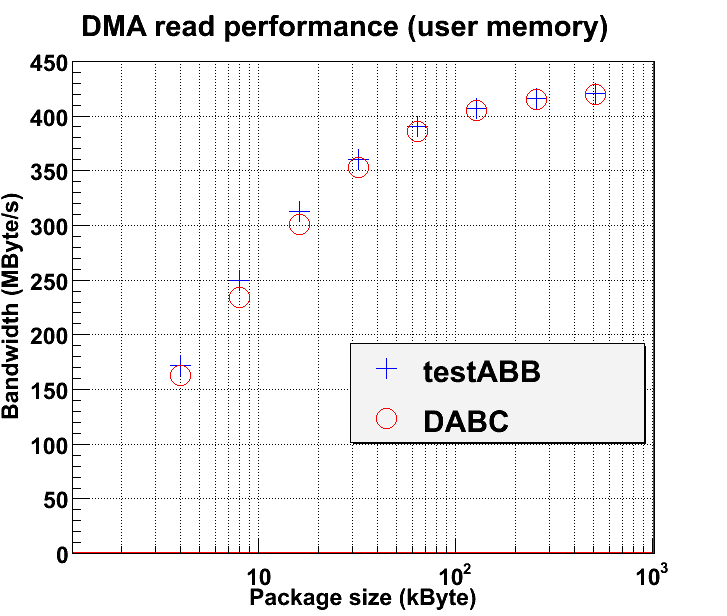
The following plot compares the AbbReadoutModule in standalone mode, reading data from AbbDevice and discarding it immeadetily, with the plain testABB benchmark as delivered with mprace library. Note the performance difference if dabc uses one single thread for PCITransport and AbbReadoutModule, or two different threads, resp. :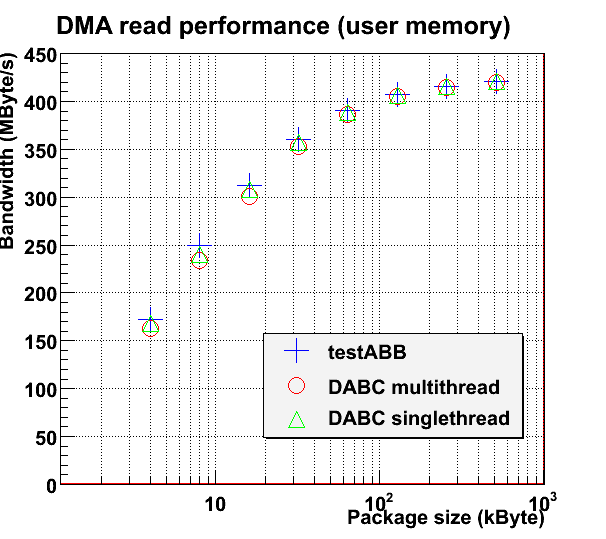 The performance loss for small packages is due to a latency overhead
The performance loss for small packages is due to a latency overhead 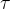 of AbbDevice, AbbReadoutModule , and the mapping of dabc buffers to dma buffers.
From the bandwidth definitions as transferred packet size
of AbbDevice, AbbReadoutModule , and the mapping of dabc buffers to dma buffers.
From the bandwidth definitions as transferred packet size 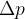 in the time interval
in the time interval  for dabc (dabc) and plain testABB measurements (mprace), one gets:
%BEGINLATEX%
\begin{equation}
B_{dabc}={\Delta p \over \Delta t + \tau}
\end{equation}
and
\begin{equation}
B_{mprace}={\Delta p \over \Delta t}
\end{equation}
$\Rightarrow $
\begin{equation}
\tau=\Delta p \cdot \left( {1 \over B_{dabc}} - {1 \over B_{mprace}} \right)
\end{equation}
%ENDLATEX%
The following plot shows the calculated values of for different package sizes for the single thread, and the multiple thread readout:
for dabc (dabc) and plain testABB measurements (mprace), one gets:
%BEGINLATEX%
\begin{equation}
B_{dabc}={\Delta p \over \Delta t + \tau}
\end{equation}
and
\begin{equation}
B_{mprace}={\Delta p \over \Delta t}
\end{equation}
$\Rightarrow $
\begin{equation}
\tau=\Delta p \cdot \left( {1 \over B_{dabc}} - {1 \over B_{mprace}} \right)
\end{equation}
%ENDLATEX%
The following plot shows the calculated values of for different package sizes for the single thread, and the multiple thread readout:
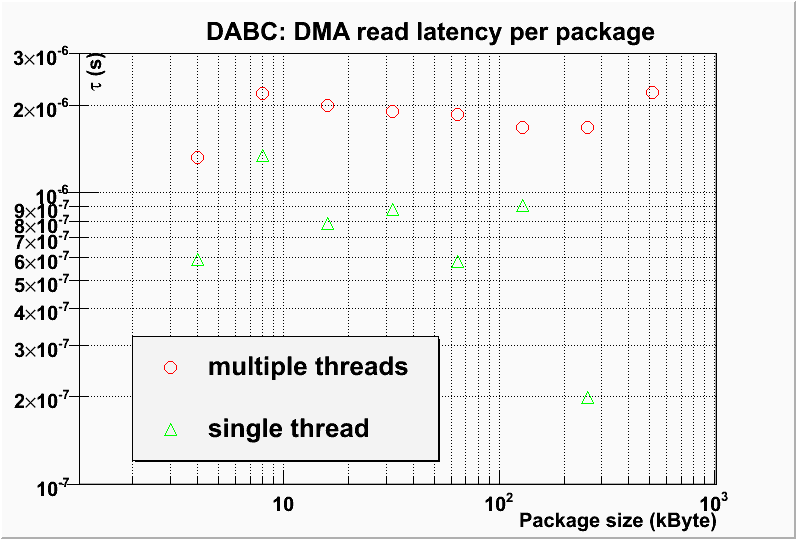 This shows a dabc latency per package which is approximately constant. A fit to these data yields typical values of
This shows a dabc latency per package which is approximately constant. A fit to these data yields typical values of
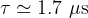 for two different threads for dabc::PCITransport and dabc::AbbReadoutModule, and
for two different threads for dabc::PCITransport and dabc::AbbReadoutModule, and
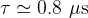 if one thread is used for both working processors, resp.
The increased latency in case of multiple threads might mostly stem from the process context switch between the two threads.
For package sizes > 64 kByte this performance penalty is neglectible.
if one thread is used for both working processors, resp.
The increased latency in case of multiple threads might mostly stem from the process context switch between the two threads.
For package sizes > 64 kByte this performance penalty is neglectible.
Bnet example
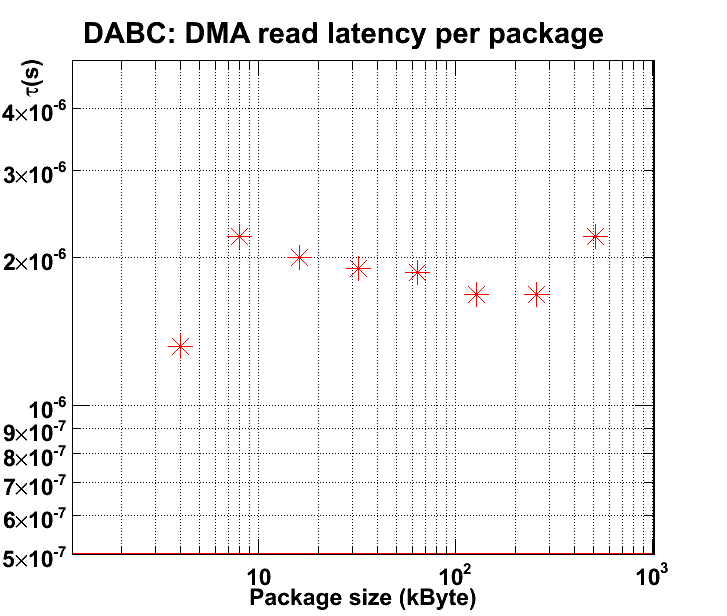
Set up: 1 ABB device as readout on node01, and 3 test generator modules as readout on each of master, node02, node03. Use verbs connection. The following plots show performance results: DMA performance comparison between dabc::AbbDevice in bnet setup, dabc::AbbDevice with standalone AbbReadoutmodule, and plain testABB program of mprace library: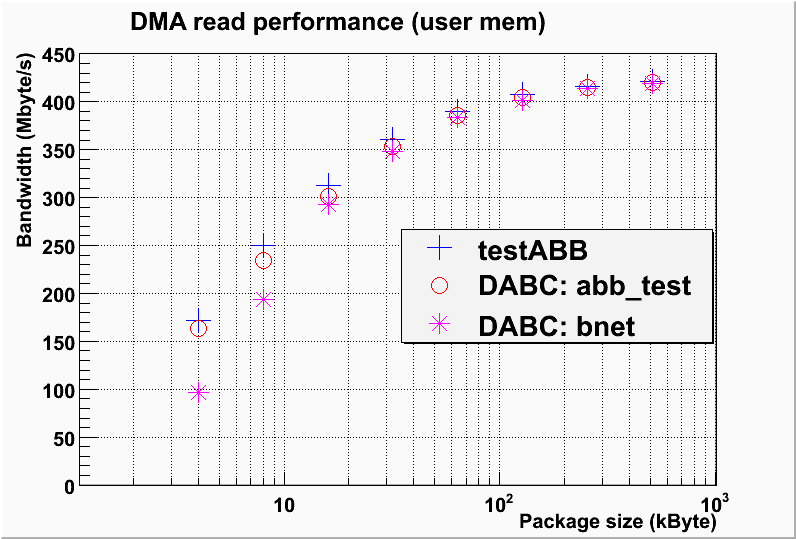 DMA read latency per package for DABC readout from ABB in bnet set up, from comparison with testABB bandwidth:
DMA read latency per package for DABC readout from ABB in bnet set up, from comparison with testABB bandwidth: 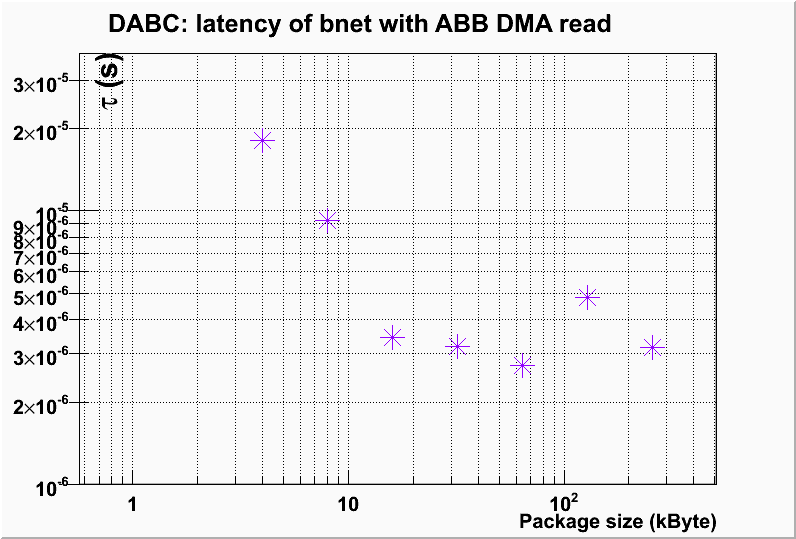 For 32k buffer size (regular dabc memory pool buffers mapped to dma buffers) the AbbReadout module
achieved a rate of ~350 Mbyte/s ("Network rate" was ~261 Mbyte/s).
When replacing the AbbDevice by regular bnet::TestGeneratorModule, one achieves 780 Mbyte/s (or 600Mbyte/s "Network" rate, resp.). The bnet is thus limited by the ABB speed for DMA read.
-- JoernAdamczewski - 10 Jun 2008
For 32k buffer size (regular dabc memory pool buffers mapped to dma buffers) the AbbReadout module
achieved a rate of ~350 Mbyte/s ("Network rate" was ~261 Mbyte/s).
When replacing the AbbDevice by regular bnet::TestGeneratorModule, one achieves 780 Mbyte/s (or 600Mbyte/s "Network" rate, resp.). The bnet is thus limited by the ABB speed for DMA read.
-- JoernAdamczewski - 10 Jun 2008
Standalone mode with AbbWriterModule
In analogy to the AbbReadoutModule, the AbbWriterModule sends (empty) buffers from the memory pool to the AbbDevice for DMA write. The following plot shows measured DMA bandwidth vs packet size of the standalone AbbWriterModule in comparison with the plain testABB program of mprace library: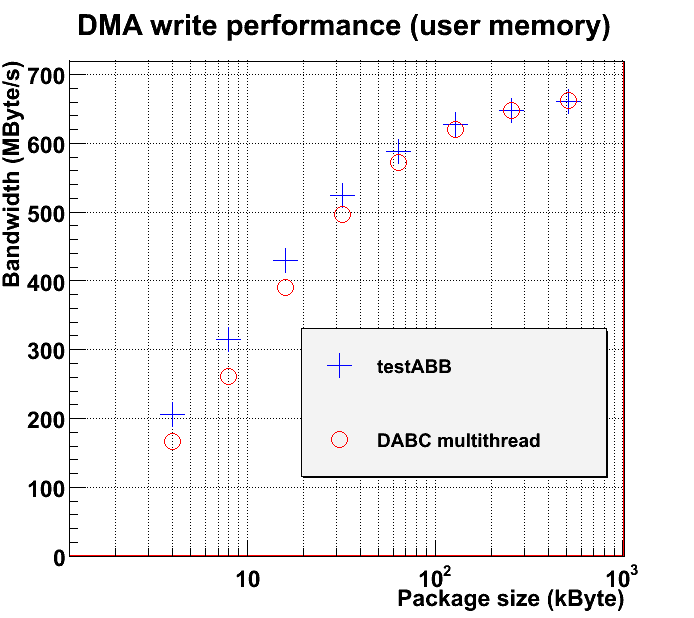 Note that Active Buffer Board in our test machine reaches faster performance for writing than for reading.
Similar to the DMA read case, the performance difference to testABB can be expressed as DABC latency per packet, as described in equations above. In the following plot latencies per packet are compared between standalone DMA read and DMA write tests:
Note that Active Buffer Board in our test machine reaches faster performance for writing than for reading.
Similar to the DMA read case, the performance difference to testABB can be expressed as DABC latency per packet, as described in equations above. In the following plot latencies per packet are compared between standalone DMA read and DMA write tests: 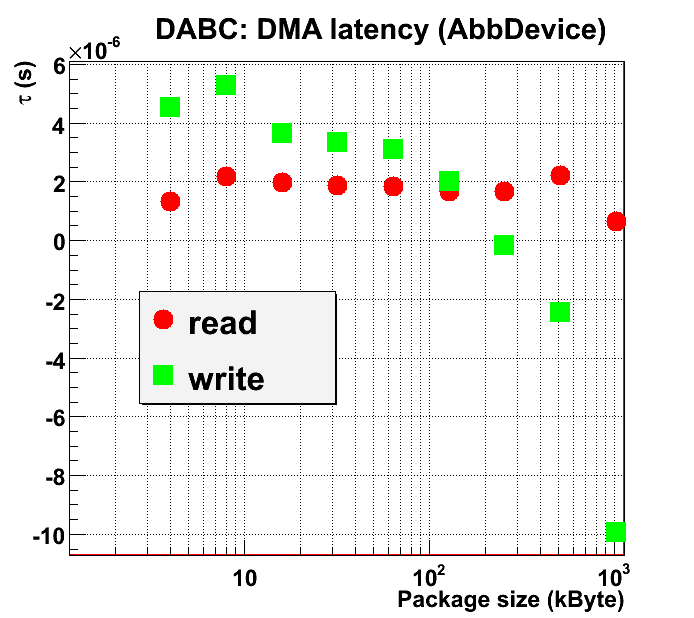 For DMA write, the latency becomes even negative, i.e. actually is not the latency of DABC only, but rather the difference between the "true" latencies of testABB and DABC. The very large value of
For DMA write, the latency becomes even negative, i.e. actually is not the latency of DABC only, but rather the difference between the "true" latencies of testABB and DABC. The very large value of 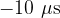 , however, may stem from inaccurately calculated value due to error propagation of the small bandwidth differences for big packets.
-- JoernAdamczewski - 16 Jun 2008
, however, may stem from inaccurately calculated value due to error propagation of the small bandwidth differences for big packets.
-- JoernAdamczewski - 16 Jun 2008
Standalone mode with concurrent AbbWriterModule and AbbReadoutModule
Concurrent DMA with writer and reader module in different threads, but using the same memory pool. Following picture shows bandwidth measured in each module (3 runs a 60s each packet size). Also shown is sum of both bandwidth for each measurement.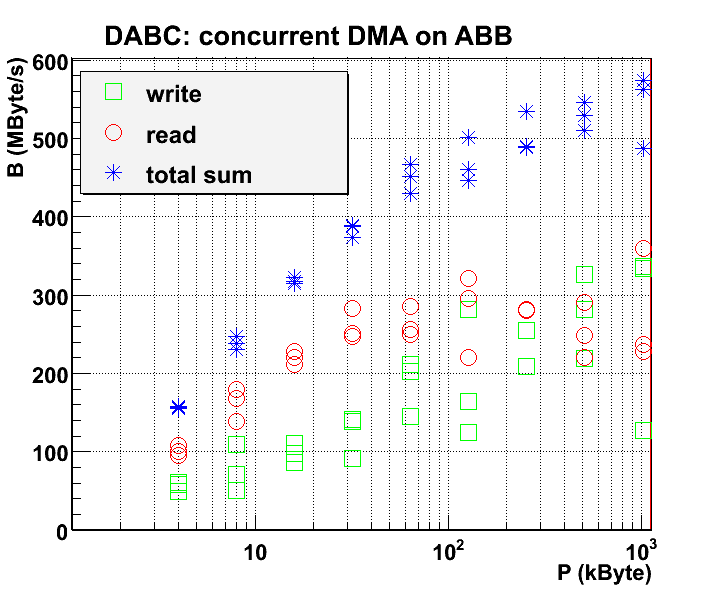 Note that there is large variance of read and write bandwidth between single meausrement runs. However, sum of both bandwidth tends to have a definite value over the runs.
Following plot shows latencies for DMA read and DMA write (in comparison with the plain testABB Bandwidth, see description above). Additionally, the transfer times for plain DMA (measured with testABB) is shown.
Note that there is large variance of read and write bandwidth between single meausrement runs. However, sum of both bandwidth tends to have a definite value over the runs.
Following plot shows latencies for DMA read and DMA write (in comparison with the plain testABB Bandwidth, see description above). Additionally, the transfer times for plain DMA (measured with testABB) is shown.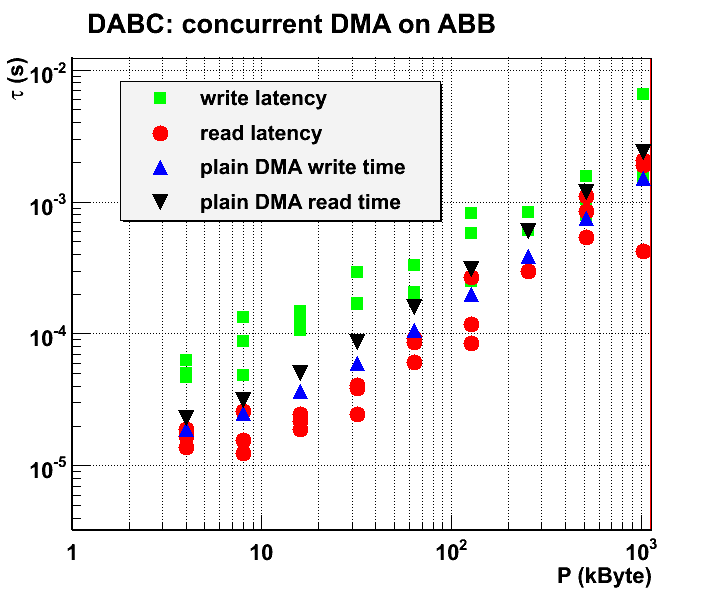 Note that latencies have the trend to follow approximately the DMA transfer time, i.e. a DMA write has to wait until the DMA read is finished before the next packet is set up (and vice versa). This effect is due to the fact that ABB DMA engine blocks next DMA start command until previous DMA is done? (Independent DMA channels upstream/downstream?). Or may show that both threads are synchronized by common DABC memory pool?
TODO: set up with different memory pools for both channels
-- JoernAdamczewski - 20 Jun 2008
Note that latencies have the trend to follow approximately the DMA transfer time, i.e. a DMA write has to wait until the DMA read is finished before the next packet is set up (and vice versa). This effect is due to the fact that ABB DMA engine blocks next DMA start command until previous DMA is done? (Independent DMA channels upstream/downstream?). Or may show that both threads are synchronized by common DABC memory pool?
TODO: set up with different memory pools for both channels
-- JoernAdamczewski - 20 Jun 2008

| I | Attachment | Action | Size | Date | Who | Comment |
|---|---|---|---|---|---|---|
| |
dabc_dma_compare.png | manage | 22 K | 2008-06-09 - 14:35 | JoernAdamczewski | DMA performance comparison of dabc::AbbDevice with standalone AbbReadoutmodule vs. plain testABB program of mprace library |
| |
dabc_dma_compare2.png | manage | 20 K | 2008-06-10 - 14:15 | JoernAdamczewski | DMA performance comparison of dabc::AbbDevice with standalone AbbReadoutmodule (one or two threads, resp.) vs. plain testABB program of mprace library |
| |
dabc_dma_compare3.png | manage | 23 K | 2008-06-10 - 17:40 | JoernAdamczewski | DMA performance comparison between dabc::AbbDevice in bnet setup, dabc::AbbDevice with standalone AbbReadoutmodule, and plain testABB program of mprace library |
| |
dabc_dma_compare_write.png | manage | 20 K | 2008-06-16 - 09:50 | JoernAdamczewski | DMA performance comparison of dabc::AbbDevice with standalone AbbWriterModule vs. plain testABB program of mprace library |
| |
dabc_dma_concurrent.png | manage | 20 K | 2008-06-20 - 15:40 | JoernAdamczewski | concurrent DMA performances with ABB (DABC standalone modules) |
| |
dabc_dma_latency.png | manage | 18 K | 2008-06-09 - 14:36 | JoernAdamczewski | DMA read latency per package for standalone DABC readout from ABB |
| |
dabc_dma_latency2.png | manage | 21 K | 2008-06-10 - 14:16 | JoernAdamczewski | DMA read latency per package for standalone DABC readout from ABB with one thread, or with separate module and transport thread, resp. |
| |
dabc_dma_latency3.png | manage | 20 K | 2008-06-10 - 17:42 | JoernAdamczewski | DMA read latency per package for DABC readout from ABB in bnet set up |
| |
dabc_dma_latency_concurrent2.png | manage | 19 K | 2008-06-20 - 15:41 | JoernAdamczewski | Concurrent DMA latencies (DABC) and plain DMA transfer times (testABB) |
| |
dabc_dma_latency_rw.png | manage | 17 K | 2008-06-16 - 09:54 | JoernAdamczewski | DMA read and DMA write latencies (DABC standalone reader/writer modules, difference to testABB) |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
This topic: DABC > Daq4FAIR > ActiveBufferBoard > ABBinDABC
Topic revision: 2008-06-20, JoernAdamczewski
Topic revision: 2008-06-20, JoernAdamczewski
Ideas, requests, problems regarding GSI Wiki? Send feedback | Legal notice | Privacy Policy (german)